

I had an e-commerce company reach out to me earlier in the year for help. They wanted to have an audit completed after making some important changes to their site.
As part of our initial communication, they prepared a bulleted list of changes that had been implemented so I would be aware of them before analyzing the site. That list included any changes in rankings, traffic and indexation.
One of those bullets stood out: They had seen a big spike in indexation after the recent changes went live. Now, this is a site that had been impacted by major algorithm updates over the years, so the combination of big site changes (without SEO guidance) and a subsequent spike in indexation scared the living daylights out of me.
 Credit: GIPHY
Credit: GIPHY
I checked Google Search Console (GSC), and this is what I saw: 6,560 pages indexed jumped to 16,215 in one week. That’s an increase of 160 percent.
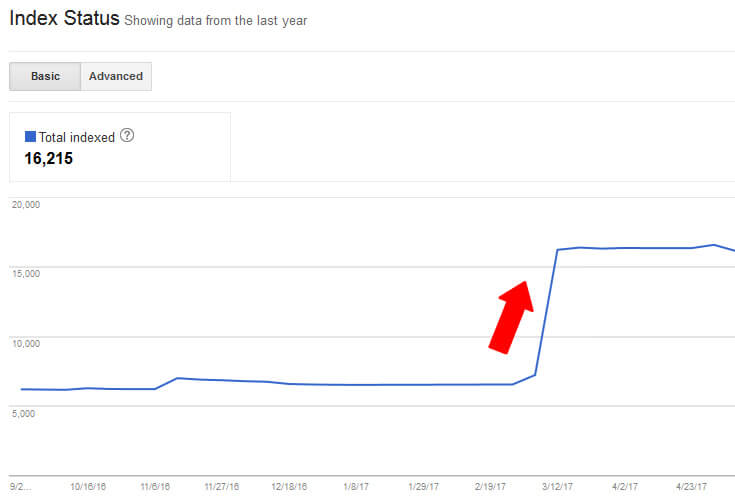
It was clear that digging into this problem and finding out what happened would be a priority. My hope was that if mistakes were pushed to production, and the wrong pages were being indexed, I could surface those problems and fix them before any major damage was done.
I unleashed Screaming Frog and DeepCrawl on the site, using both Googlebot and Googlebot for Smartphones as the user-agents. I was eager to dig into the crawl data.
The problem: Mobile faceted navigation and a surge in thin content
First, the site is not responsive. Instead, it uses dynamic serving, which means different HTML and CSS can be delivered based on user-agent.
The recent changes were made to the mobile version of the site. After those changes were implemented, Googlebot was being driven to many thin URLs via a faceted navigation (only available on the mobile pages). Those thin URLs were clearly being indexed. At a time where Google’s quality algorithms seem to be on overload, that’s never a good thing.
The crawls I performed surfaced a number of pages based on the mobile faceted navigation — and many of them were horribly thin or blank. In addition, the HTML Improvements report (yes, that report many people totally ignore) listed a number of those thin URLs in the duplicate title tags report.
I dug into GSC while the crawls were running and started surfacing many of those problematic URLs. Here’s a screen shot showing close to 4,000 thin URLs in the report. That wasn’t all of the problematic URLs, but you could see Google was finding them.
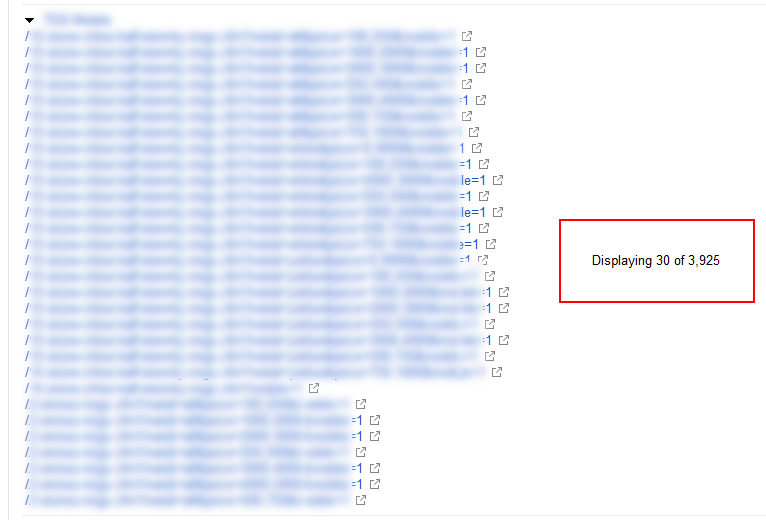
We clearly had a situation where technical SEO problems led to thin content. I’ve mentioned this problem many times while writing about major algorithm updates, and this was a great example of that happening. Now, it was time to collect as much data as possible, and then communicate the core problems to my client.
The fix
The first thing I explained was that the mobile-first index would be coming soon, and it would probably be best if the site were moved to a responsive design. Then my client could be confident that all of the pages contained the same content, structured data, directives and so on. They agreed with me, and that’s the long-term goal for the site.
Second, and directly related to the problem I surfaced, I explained that they should either canonicalize, noindex or 404 all of the thin pages being linked to from the faceted navigation on mobile. As Googlebot crawls those pages again, it should pick up the changes and start dropping them from the index.
My client asked about blocking via robots.txt, and I explained that if the pages are blocked, then Googlebot will never see the noindex tag. That’s a common question, and I know there’s a lot of confusion about that.

It’s only after those pages are removed from the index that they should be blocked via robots.txt (if you choose to go down that path). My client actually decided to 404 the pages, rolled out the changes, and then moved on to other important findings from the audit and crawl analysis.
The question
And then my client asked an important question. It’s one that many have asked after noindexing or removing low-quality or thin pages from their sites.
“How long will it take for Google to drop those pages from the index??”
[Read the full article on Search Engine Land.]
Some opinions expressed in this article may be those of a guest author and not necessarily Marketing Land. Staff authors are listed here.
About The Author

Glenn Gabe, president of G-Squared Interactive, is a digital marketing veteran with over 20 years of experience. Glenn currently helps clients maximize their online marketing efforts via Search Engine Optimization (SEO), Search Engine Marketing (SEM), Social Advertising, and Web Analytics. During the past 20 years, Glenn has assisted clients across a wide range of industries including consumer packaged goods (CPG), e-commerce retailers, startups, pharmaceuticals, healthcare, military, education, non-profits, online auctions, real estate, and publishing.
Popular Stories
Related Topics